OpenThread architectures¶
This page describes the OpenThread stack architecture and platform designs that are possible with the OpenThread network stack on Nordic Semiconductor devices in nRF Connect SDK.
The designs are described from the least complex to the most complex, starting with System-on-Chip designs. These are simple applications that consist of a single chip running a single protocol or multiple protocols. Co-processor designs, on the other hand, require two processors. The nRF SoC acts as a network co-processor, while the application is running on a much more powerful host processor.
OpenThread stack architecture¶
OpenThread’s portable nature makes no assumptions about platform features. OpenThread provides the hooks to use enhanced radio and cryptography features, reducing system requirements, such as memory, code, and compute cycles. This can be done per platform, while retaining the ability to default to a standard configuration.
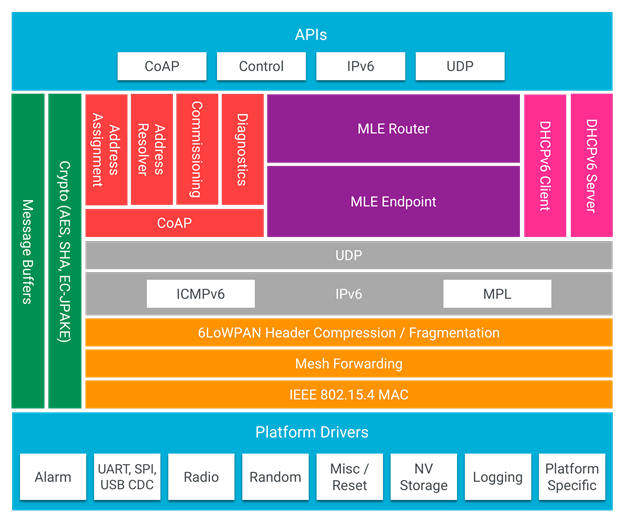
OpenThread architecture adapted from openthread.io¶
System-on-Chip designs¶
A single-chip solution uses the RFIC (the IEEE 802.15.4 in case of Thread) and the processor of a single SoC.
In these designs, OpenThread and the application layer run on the same local processor.
Single-chip, single protocol (SoC)¶
In this design, the only wireless protocol that is used is Thread. OpenThread and the application layer run on the same processor. The application uses the OpenThread APIs and IPv6 stack directly.
This SoC design is most commonly used for applications that do not make heavy computations or are battery-powered.
This design has the following advantages:
The radio and the general MCU functionalities are combined into one chip, resulting in a low cost.
Power consumption is lower than in all other designs.
Complexity is lower than in all other designs.
It has the following disadvantages:
For some use cases, the nRF52 Series and nRF53 Series MCUs can be too slow (for example, when the application does complex data processing).
The application and the network share flash and RAM space, which can limit the application functionality.
Dual-bank DFU or an external flash is needed to update the firmware.

Thread-only architecture on nRF52 Series devices¶

Thread-only architecture on nRF53 Series devices¶
This platform design is suitable for the following development kits:
Hardware platforms |
PCA |
Board name |
Build target |
|---|---|---|---|
PCA10056 |
|
||
PCA10100 |
|
||
PCA10095 |
|
||
nRF21540 DK |
PCA10112 |
|
Single-chip, multiprotocol (SoC)¶
nRF52 and nRF53 Series devices support multiple wireless technologies, including IEEE 802.15.4 and Bluetooth® Low Energy (Bluetooth LE).
In a single-chip, multiprotocol design, the application layer and OpenThread run on the same processor.
This design has the following advantages:
It leverages the benefits of a highly integrated SoC, resulting in low cost and low power consumption.
It allows to run Thread and Bluetooth LE simultaneously on a single chip, which reduces the overall BOM cost.
It has the following disadvantages:
Bluetooth LE activity can degrade the connectivity on Thread if not implemented with efficiency in mind.

Multiprotocol Thread and Bluetooth LE architecture on nRF52 Series devices¶

Multiprotocol Thread and Bluetooth LE architecture on nRF53 Series devices¶
For more information about the multiprotocol feature, see Multiprotocol support.
This platform design is suitable for the following development kits:
Hardware platforms |
PCA |
Board name |
Build target |
|---|---|---|---|
PCA10056 |
|
||
PCA10100 |
|
||
PCA10095 |
|
Co-processor designs¶
In co-processor designs, the application runs on one processor (the host processor) and communicates with another processor that provides the Thread radio. The communication happens through a serial connection using a standardized host-controller protocol (Spinel).
OpenThread runs on either the radio processor or the host processor, depending on whether a network co-processor (NCP) design or a radio co-processor (RCP) design is chosen.
Network co-processor (NCP)¶
In the standard NCP design, the full OpenThread stack runs on the processor that provides the Thread radio (the network processor), and the application layer runs on a host processor. The host processor is typically more capable than the network processor, but it has greater power demands. The host processor communicates with the network processor through a serial interface (typically UART or SPI) over the Spinel protocol.
This design is useful for gateway devices or devices that have other processing demands, like IP cameras and speakers.
This design has the following advantages:
The higher-power host can sleep, while the lower-power network processor remains active to maintain its place in the Thread network.
Since the network processor is not tied to the application layer, development and testing of applications is independent of the OpenThread build.
When choosing an advanced and powerful host processor, applications can be very complex.
Only the network stack and a thin application reside on the network processor, which reduces the cost of the chip. RAM and flash usage are usually smaller than in a single-chip solution.
This design does not require support for dual-bank DFU, because the host can just replace the old image with a new one.
It has the following disadvantages:
This is a more expensive option, because it requires a host processor for the application.

Network co-processor architecture¶
Note
Spinel connections through SPI and USB are not currently available.
This platform design is suitable for the following development kits:
Hardware platforms |
PCA |
Board name |
Build target |
|---|---|---|---|
PCA10056 |
|
||
PCA10100 |
|
||
nRF21540 DK |
PCA10112 |
|
Radio co-processor (RCP)¶
This is a variant of the NCP design where the core of OpenThread runs on the host processor, with only a minimal “controller” running on the device with the Thread radio. In this design, the host processor typically does not sleep, to ensure reliability of the Thread network.
This design is useful for devices that are less sensitive to power constraints.
This design has the following advantages:
OpenThread can use the resources on the more powerful host processor.
When choosing an advanced and powerful host processor, applications can be very complex.
It is possible to use a radio co-processor that is less capable than what is needed in the NCP design, which reduces the cost.
It has the following disadvantages:
The host processor must be woken up on each received frame, even if a frame must be forwarded to the neighboring device.
The RCP solution can be less responsive than the NCP solution, due to the fact that each frame or command must be communicated to the host processor over the serial link.

Radio co-processor architecture¶
Note
Spinel connections through SPI and USB are not currently available.
This platform design is suitable for the following development kits:
Hardware platforms |
PCA |
Board name |
Build target |
|---|---|---|---|
PCA10056 |
|
||
PCA10100 |
|
||
nRF21540 DK |
PCA10112 |
|
NCP/RCP communication details¶
The NCP/RCP transport architectures include a transmit (TX) buffer that stores all the data that are to be received by the host using the Spinel protocol.
NCP/RCP prioritization¶
Since the Spinel protocol does not enforce any prioritization for writing data, the OpenThread NCP and RCP architectures introduce a data prioritization of their own:
High priority – for data in the TX buffer that must be written, including data that must be written as fast as possible.
Low priority – for data in the TX buffer that can be delayed or can be dropped if a high priority message is awaiting to be written.
When the buffer is full, some of the low priority frames cannot be dropped and are delayed for later transmission. This happens for example with the Unsolicited update commands, where the low priority frames are themselves prioritized in the following order:
Frames that can be delayed for later transmission (“delayable frames”).
Frames that cannot be delayed and are dropped when the TX buffer is full (“droppable frames”).
Receiving and transmitting data¶
The Spinel communication is based on commands and responses. The host sends commands to NCP/RCP, and expects a response to each of them.
The commands and responses are tied together with the Transaction Identifier value (TID value) in the Spinel frame header. Responses have a non-zero TID value, and OpenThread NCP/RCP always gives them high priority.
The pending responses that do not fit into the TX buffer are queued for later execution. The queue is itself a buffer located above the TX buffer. If it is full or contains any pending responses, sending of the delayable frames is postponed and all other low priority data is dropped.
Moreover, the Spinel allows sending unsolicited update commands from NCP to the host, as well as sending logs. See Transmitting data for details.
Receiving data and RX data flows¶
The section illustrates the RX data flows for UART and SPI for when the commands are received by NCP/RCP:
Data RX flow for UART

Data RX flow for UART¶
In this flow:
UART interface stores up to 6 bytes in the hardware FIFO.
HDLC-encoded data is stored in the Driver receive buffer.
HDLC data is decoded and stored in the NCP UART Driver receive buffer.
Spinel commands are dispatched and handled by proper routines.
If a command requires a response, it will be added to the NCP response queue for later execution.
Data RX flow for SPI

Data RX flow for SPI¶
In this flow:
SPI interface saves data into the NCP SPI RX buffer.
NCP obtains pointer to the Spinel frame in the buffer and handles it.
If a command requires a response, it will be added to the NCP response queue for later execution.
Transmitting data¶
NCP/RCP has the following process for sending responses:
After a command is received, the response ends up in the NCP/RCP Response Queue.
In the NCP/RCP Response Queue, the command is checked for the data required by the host.
NCP/RCP gathers the data and writes the response to the TX buffer by emptying the NCP/RCP Response Queue.
The process of writing the frames to the buffer is described in the Writing to the buffer paragraph.
NCP/RCP sends the response from the TX buffer to the host.
Unsolicited update commands¶
The Spinel also allows sending unsolicited update commands from NCP to the host, for example when NCP or a node receives a IPv6 packet that must be forwarded to the host.
The unsolicited update commands have the following characteristics:
They are written to the TX buffer.
They are asynchronous.
All have the TID value equal to zero.
They have low priority.
The unsolicited update commands include both delayable and droppable frames (see NCP/RCP prioritization), prioritized in the following order:
Delayable frames:
MAC, IPv6 and UDP forwarding stream properties.
Property value notification commands, including last status update.
Droppable frames:
Debug stream for application.
This is a separate log for application that has a property ID field that allows the application to distinguish different debug streams.
Log.
This is a log that can be used to report errors and debug information in the OpenThread stack and in Zephyr to the host using Spinel.
Writing to the buffer¶
The responses and unsolicited update commands are written to the buffer using the following process:
NCP/RCP attempts to empty the NCP/RCP Response Queue. If any response remains in the queue, it prevents the lower priority messages from being written to the buffer.
Network frames from the Thread stack are added to the queue and a reattempt is made later.
Property value notification commands are not sent and a reattempt is made later.
Log and debug stream frames are dropped.
NCP/RCP attempts to empty the OT Message Queue for pending MAC, IPv6, and UDP messages. The data from these pending messages is not directly copied into the NCP TX Buffer, but instead it is stored in the OT stack and associated with the Spinel frame. The data is copied just before transmission over UART/USB/SPI. This helps save the TX buffer space.
NCP/RCP attempts to send all pending property value notification commands.
If the buffer space is available and no responses are pending in the NCP/RCP Response Queue, NCP/RCP allows the logs and debug stream to be written to the TX buffer.
TX data flows¶
This section illustrates TX data flows for UART and SPI when sending responses and writing them to the TX buffer:


Log messages and raw data through Spinel¶
Although by default Spinel communication is based on commands and responses, logs from OpenThread and from Zephyr system can also be encoded and transmitted using Spinel. This allows for using only one interface for frame and log transmission.
However, when using NCP with Zephyr, there is still a possibility that NCP will transmit raw data, without encoding it into Spinel frames. This happens when some critical errors occur in Zephyr and the system wants to provide as much information about the failure as possible without using interrupts. This exception applies mainly to log messages and is done by turning off UART interrupts and flushing everything from the TX buffer without encoding it.
Portions of this page are reproduced from work created and shared by Google, and used according to terms described in the Creative Commons 4.0 Attribution License. The source page is available here.