Real Time I/O (RTIO)
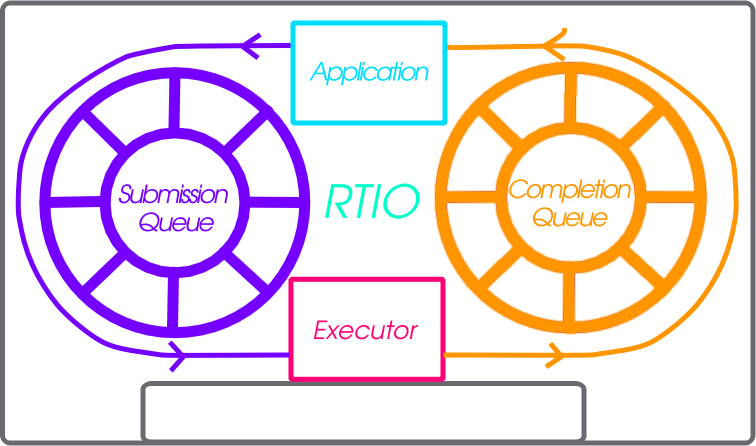
RTIO provides a framework for doing asynchronous operation chains with event driven I/O. This section covers the RTIO API, queues, executor, iodev, and common usage patterns with peripheral devices.
RTIO takes a lot of inspiration from Linux’s io_uring in its operations and API as that API matches up well with hardware DMA transfer queues and descriptions.
A quick sales pitch on why RTIO works well in many scenarios:
API is DMA and interrupt friendly
No buffer copying
No callbacks
Blocking or non-blocking operation
Problem
An application wishing to do complex DMA or interrupt driven operations today in Zephyr requires direct knowledge of the hardware and how it works. There is no understanding in the DMA API of other Zephyr devices and how they relate.
This means doing complex audio, video, or sensor streaming requires direct hardware knowledge or leaky abstractions over DMA controllers. Neither is ideal.
To enable asynchronous operations, especially with DMA, a description of what to do rather than direct operations through C and callbacks is needed. Enabling DMA features such as channels with priority, and sequences of transfers requires more than a simple list of descriptions.
Using DMA and/or interrupt driven I/O shouldn’t dictate whether or not the call is blocking or not.
Inspiration, introducing io_uring
It’s better not to reinvent the wheel (or ring in this case) and io_uring as an API from the Linux kernel provides a winning model. In io_uring there are two lock-free ring buffers acting as queues shared between the kernel and a userland application. One queue for submission entries which may be chained and flushed to create concurrent sequential requests. A second queue for completion queue events. Only a single syscall is actually required to execute many operations, the io_uring_submit call. This call may block the caller when a number of operations to wait on is given.
This model maps well to DMA and interrupt driven transfers. A request to do a sequence of operations in an asynchronous way directly relates to the way hardware typically works with interrupt driven state machines potentially involving multiple peripheral IPs like bus and DMA controllers.
Submission Queue and Chaining
The submission queue (sq), is the description of the operations to perform in concurrent chains.
For example imagine a typical SPI transfer where you wish to write a register address to then read from. So the sequence of operations might be…
Chip Select
Clock Enable
Write register address into SPI transmit register
Read from the SPI receive register into a buffer
Disable clock
Disable Chip Select
If anything in this chain of operations fails give up. Some of those operations can be embodied in a device abstraction that understands a read or write implicitly means setup the clock and chip select. The transactional nature of the request also needs to be embodied in some manner. Of the operations above perhaps the read could be done using DMA as its large enough make sense. That requires an understanding of how to setup the device’s particular DMA to do so.
The above sequence of operations is embodied in RTIO as chain of submission queue entries (sqe). Chaining is done by setting a bitflag in an sqe to signify the next sqe must wait on the current one.
Because the chip select and clocking is common to a particular SPI controller and device on the bus it is embodied in what RTIO calls an iodev.
Multiple operations against the same iodev are done in the order provided as soon as possible. If two operation chains have varying points using the same device its possible one chain will have to wait for another to complete.
Completion Queue
In order to know when a sqe has completed there is a completion queue (cq) with completion queue events (cqe). A sqe once completed results in a cqe being pushed into the cq. The ordering of cqe may not be the same order of sqe. A chain of sqe will however ensure ordering and failure cascading.
Other potential schemes are possible but a completion queue is a well trod idea with io_uring and other similar operating system APIs.
Executor and IODev
Turning submission queue entries (sqe) into completion queue events (cqe) is the job of objects implementing the executor and iodev APIs. These APIs enable coordination between themselves to enable things like DMA transfers.
The end result of these APIs should be a method to resolve the request by deciding some of the following questions with heuristic/constraint based decision making.
Polling, Interrupt, or DMA transfer?
If DMA, are the requirements met (peripheral supported by DMAC, etc).
The executor is meant to provide policy for when to use each transfer type, and provide the common code for walking through submission queue chains by providing calls the iodev may use to signal completion, error, or a need to suspend and wait.
Outstanding Questions
RTIO is not a complete API and solution, and is currently evolving to best fit the nature of an RTOS. The general ideas behind a pair of queues to describe requests and completions seems sound and has been proven out in other contexts. Questions remain though.
Timeouts and Deadlines
Timeouts and deadlines are key to being Real-Time. Real-Time in Zephyr means being able to do things when an application wants them done. That could mean different things from a deadline with best effort attempts or a timeout and failure.
These features would surely be useful in many cases, but would likely add some significant complexities. It’s something to decide upon, and even if enabled would likely be a compile time optional feature leading to complex testing.
Cancellation
Canceling an already queued operation could be possible with a small API addition to perhaps take both the RTIO context and a pointer to the submission queue entry. However, cancellation as an API induces many potential complexities that might not be appropriate. It’s something to be decided upon.
Userspace Support
RTIO with userspace is certainly plausible but would require the equivalent of a memory map call to map the shared ringbuffers and also potentially dma buffers.
Additionally a DMA buffer interface would likely need to be provided for coherence and MMU usage.
IODev and Executor API
Lastly the API between an executor and iodev is incomplete.
There are certain interactions that should be supported. Perhaps things like expanding a submission queue entry into multiple submission queue entries in order to split up work that can be done by a device and work that can be done by a DMA controller.
In some SoCs only specific DMA channels may be used with specific devices. In others there are requirements around needing a DMA handshake or specific triggering setups to tell the DMA when to start its operation.
None of that, from the outward facing API, is an issue.
It is however an unresolved task and issue from an internal API between the executor and iodev. This requires some SoC specifics and enabling those generically isn’t likely possible. That’s ok, an iodev and dma executor should be vendor specific, but an API needs to be there between them that is not!
Special Hardware: Intel HDA
In some cases there’s a need to always do things in a specific order with a specific buffer allocation strategy. Consider a DMA that requires the usage of a circular buffer segmented into blocks that may only be transferred one after another. This is the case of the Intel HDA stream for audio.
In this scenario the above API can still work, but would require an additional buffer allocator to work with fixed sized segments.
When to Use
It’s important to understand when DMA like transfers are useful and when they are not. It’s a poor idea to assume that something made for high throughput will work for you. There is a computational, memory, and latency cost to setup the description of transfers.
Polling at 1Hz an air sensor will almost certainly result in a net negative result compared to ad-hoc sensor (i2c/spi) requests to get the sample.
Continuous transfers, driven by timer or interrupt, of data from a peripheral’s on board FIFO over I2C, I3C, SPI, MIPI, I2S, etc… maybe, but not always!
Examples
Examples speak loudly about the intended uses and goals of an API. So several key examples are presented below. Some are entirely plausible today without a big leap. Others (the sensor example) would require additional work in other APIs outside of RTIO as a sub system and are theoretical.
Chained Blocking Requests
A common scenario is needing to write the register address to then read from. This can be accomplished by chaining a write into a read operation.
The transaction on i2c is implicit for each operation chain.
RTIO_I2C_IODEV(i2c_dev, I2C_DT_SPEC_INST(n));
RTIO_DEFINE(ez_io, 4, 4);
static uint16_t reg_addr;
static uint8_t buf[32];
int do_some_io(void)
{
struct rtio_sqe *write_sqe = rtio_spsc_acquire(ez_io.sq);
struct rtio_sqe *read_sqe = rtio_spsc_acquire(ez_io.sq);
rtio_sqe_prep_write(write_sqe, i2c_dev, RTIO_PRIO_LOW, ®_addr, 2);
write_sqe->flags = RTIO_SQE_CHAINED; /* the next item in the queue will wait on this one */
rtio_sqe_prep_read(read_sqe, i2c_dev, RTIO_PRIO_LOW, buf, 32);
rtio_submit(rtio_inplace_executor, &ez_io, 2);
struct rtio_cqe *read_cqe = rtio_spsc_consume(ez_io.cq);
struct rtio_cqe *write_cqe = rtio_spsc_consume(ez_io.cq);
if(read_cqe->result < 0) {
LOG_ERR("read failed!");
}
if(write_cqe->result < 0) {
LOG_ERR("write failed!");
}
rtio_spsc_release(ez_io.cq);
rtio_spsc_release(ez_io.cq);
}
Non blocking device to device
Imagine wishing to read from one device on an I2C bus and then write the same buffer to a device on a SPI bus without blocking the thread or setting up callbacks or other IPC notification mechanisms.
Perhaps an I2C temperature sensor and a SPI lowrawan module. The following is a simplified version of that potential operation chain.
RTIO_I2C_IODEV(i2c_dev, I2C_DT_SPEC_INST(n));
RTIO_SPI_IODEV(spi_dev, SPI_DT_SPEC_INST(m));
RTIO_DEFINE(ez_io, 4, 4);
static uint8_t buf[32];
int do_some_io(void)
{
uint32_t read, write;
struct rtio_sqe *read_sqe = rtio_spsc_acquire(ez_io.sq);
rtio_sqe_prep_read(read_sqe, i2c_dev, RTIO_PRIO_LOW, buf, 32);
read_sqe->flags = RTIO_SQE_CHAINED; /* the next item in the queue will wait on this one */
/* Safe to do as the chained operation *ensures* that if one fails all subsequent ops fail */
struct rtio_sqe *write_sqe = rtio_spsc_acquire(ez_io.sq);
rtio_sqe_prep_write(write_sqe, spi_dev, RTIO_PRIO_LOW, buf, 32);
/* call will return immediately without blocking if possible */
rtio_submit(rtio_inplace_executor, &ez_io, 0);
/* These calls might return NULL if the operations have not yet completed! */
for (int i = 0; i < 2; i++) {
struct rtio_cqe *cqe = rtio_spsc_consume(ez_io.cq);
while(cqe == NULL) {
cqe = rtio_spsc_consume(ez_io.cq);
k_yield();
}
if(cqe->userdata == &read && cqe->result < 0) {
LOG_ERR("read from i2c failed!");
}
if(cqe->userdata == &write && cqe->result < 0) {
LOG_ERR("write to spi failed!");
}
/* Must release the completion queue event after consume */
rtio_spsc_release(ez_io.cq);
}
}
Nested iodevs for Devices on Buses (Sensors), Theoretical
Consider a device like a sensor or audio codec sitting on a bus.
Its useful to consider that the sensor driver can use RTIO to do I/O on the SPI bus, while also being an RTIO device itself. The sensor iodev can set aside a small portion of the buffer in front or in back to store some metadata describing the format of the data. This metadata could then be used in creating a sensor readings iterator which lazily lets you map over each reading, doing calculations such as FIR/IIR filtering, or perhaps translating the readings into other numerical formats with useful measurement units such as SI. RTIO is a common movement API and allows for such uses while not deciding the mechanism.
This same sort of setup could be done for other data streams such as audio or video.
/* Note that the sensor device itself can use RTIO to get data over I2C/SPI
* potentially with DMA, but we don't need to worry about that here
* All we need to know is the device tree node_id and that it can be an iodev
*/
RTIO_SENSOR_IODEV(sensor_dev, DEVICE_DT_GET(DT_NODE(super6axis));
RTIO_DEFINE(ez_io, 4, 4);
/* The sensor driver decides the minimum buffer size for us, we decide how
* many bufs. This could be a typical multiple of a fifo packet the sensor
* produces, ICM42688 for example produces a FIFO packet of 20 bytes in
* 20bit mode at 32KHz so perhaps we'd like to get 4 buffers of 4ms of data
* each in this setup to process on. and its already been defined here for us.
*/
#include <sensors/icm42688_p.h>
static uint8_t bufs[4][ICM42688_RTIO_BUF_SIZE];
int do_some_sensors(void) {
/* Obtain a dmac executor from the DMA device */
struct device *dma = DEVICE_DT_GET(DT_NODE(dma0));
const struct rtio_executor *rtio_dma_exec =
dma_rtio_executor(dma);
/*
* Set the executor for our queue context
*/
rtio_set_executor(ez_io, rtio_dma_exec);
/* Mostly we want to feed the sensor driver enough buffers to fill while
* we wait and process! Small enough to process quickly with low latency,
* big enough to not spend all the time setting transfers up.
*
* It's assumed here that the sensor has been configured already
* and each FIFO watermark interrupt that occurs it attempts
* to pull from the queue, fill the buffer with a small metadata
* offset using its own rtio request to the SPI bus using DMA.
*/
for(int i = 0; i < 4; i++) {
struct rtio_sqe *read_sqe = rtio_spsc_acquire(ez_io.sq);
rtio_sqe_prep_read(read_sqe, sensor_dev, RTIO_PRIO_HIGH, bufs[i], ICM42688_RTIO_BUF_SIZE);
}
struct device *sensor = DEVICE_DT_GET(DT_NODE(super6axis));
struct sensor_reader reader;
struct sensor_channels channels[4] = {
SENSOR_TIMESTAMP_CHANNEL,
SENSOR_CHANNEL(int32_t, SENSOR_ACC_X, 0, SENSOR_RAW),
SENSOR_CHANNEL(int32_t SENSOR_ACC_Y, 0, SENSOR_RAW),
SENSOR_CHANNEL(int32_t, SENSOR_ACC_Z, 0, SENSOR_RAW),
};
while (true) {
/* call will wait for one completion event */
rtio_submit(ez_io, 1);
struct rtio_cqe *cqe = rtio_spsc_consume(ez_io.cq);
if(cqe->result < 0) {
LOG_ERR("read failed!");
goto next;
}
/* Bytes read into the buffer */
int32_t bytes_read = cqe->result;
/* Retrieve soon to be reusable buffer pointer from completion */
uint8_t *buf = cqe->userdata;
/* Get an iterator (reader) that obtains sensor readings in integer
* form, 16 bit signed values in the native sensor reading format
*/
res = sensor_reader(sensor, buf, cqe->result, &reader, channels,
sizeof(channels));
__ASSERT(res == 0);
while(sensor_reader_next(&reader)) {
printf("time(raw): %d, acc (x,y,z): (%d, %d, %d)\n",
channels[0].value.u32, channels[1].value.i32,
channels[2].value.i32, channels[3].value.i32);
}
next:
/* Release completion queue event */
rtio_spsc_release(ez_io.cq);
/* resubmit a read request with the newly freed buffer to the sensor */
struct rtio_sqe *read_sqe = rtio_spsc_acquire(ez_io.sq);
rtio_sqe_prep_read(read_sqe, sensor_dev, RTIO_PRIO_HIGH, buf, ICM20649_RTIO_BUF_SIZE);
}
}
API Reference
RTIO API
- group rtio_api
RTIO API.
Defines
-
RTIO_OP_NOP
An operation that does nothing and will complete immediately
-
RTIO_OP_RX
An operation that receives (reads)
-
RTIO_OP_TX
An operation that transmits (writes)
-
RTIO_SQ_DEFINE(name, len)
Statically define and initialize a fixed length submission queue.
- Parameters
name – Name of the submission queue.
len – Queue length, power of 2 required (2, 4, 8).
-
RTIO_CQ_DEFINE(name, len)
Statically define and initialize a fixed length completion queue.
- Parameters
name – Name of the completion queue.
len – Queue length, power of 2 required (2, 4, 8).
-
RTIO_DEFINE(name, exec, sq_sz, cq_sz)
Statically define and initialize an RTIO context.
- Parameters
name – Name of the RTIO
exec – Symbol for rtio_executor (pointer)
sq_sz – Size of the submission queue, must be power of 2
cq_sz – Size of the completion queue, must be power of 2
Functions
-
static inline void rtio_sqe_prep_nop(struct rtio_sqe *sqe, struct rtio_iodev *iodev, void *userdata)
Prepare a nop (no op) submission.
-
static inline void rtio_sqe_prep_read(struct rtio_sqe *sqe, struct rtio_iodev *iodev, int8_t prio, uint8_t *buf, uint32_t len, void *userdata)
Prepare a read op submission.
-
static inline void rtio_sqe_prep_write(struct rtio_sqe *sqe, struct rtio_iodev *iodev, int8_t prio, uint8_t *buf, uint32_t len, void *userdata)
Prepare a write op submission.
-
static inline void rtio_set_executor(struct rtio *r, struct rtio_executor *exc)
Set the executor of the rtio context.
-
static inline void rtio_iodev_submit(const struct rtio_sqe *sqe, struct rtio *r)
Perform a submitted operation with an iodev.
- Parameters
sqe – Submission to work on
r – RTIO context
-
static inline int rtio_submit(struct rtio *r, uint32_t wait_count)
Submit I/O requests to the underlying executor.
Submits the queue of requested IO operation chains to the underlying executor. The underlying executor will decide on which hardware and with what sort of parallelism the execution of IO chains is performed.
- Parameters
r – RTIO context
wait_count – Count of completions to wait for If wait_count is for completions flag is set, the call will not return until the desired number of completions are done. A wait count of non-zero requires the caller be on a thread.
- Return values
0 – On success
-
static inline struct rtio_cqe *rtio_cqe_consume(struct rtio *r)
Consume a single completion queue event if available.
If a completion queue event is returned rtio_cq_release(r) must be called at some point to release the cqe spot for the cqe producer.
- Parameters
r – RTIO context
- Return values
cqe – A valid completion queue event consumed from the completion queue
NULL – No completion queue event available
-
static inline struct rtio_cqe *rtio_cqe_consume_block(struct rtio *r)
Wait for and consume a single completion queue event.
If a completion queue event is returned rtio_cq_release(r) must be called at some point to release the cqe spot for the cqe producer.
- Parameters
r – RTIO context
- Return values
cqe – A valid completion queue event consumed from the completion queue
-
static inline void rtio_sqe_ok(struct rtio *r, const struct rtio_sqe *sqe, int result)
Inform the executor of a submission completion with success.
This may start the next asynchronous request if one is available.
- Parameters
r – RTIO context
sqe – Submission that has succeeded
result – Result of the request
-
static inline void rtio_sqe_err(struct rtio *r, const struct rtio_sqe *sqe, int result)
Inform the executor of a submissions completion with error.
This SHALL fail the remaining submissions in the chain.
- Parameters
r – RTIO context
sqe – Submission that has failed
result – Result of the request
-
static inline void rtio_cqe_submit(struct rtio *r, int result, void *userdata)
Submit a completion queue event with a given result and userdata
Called by the executor to produce a completion queue event, no inherent locking is performed and this is not safe to do from multiple callers.
- Parameters
r – RTIO context
result – Integer result code (could be -errno)
userdata – Userdata to pass along to completion
-
struct rtio_sqe
- #include <rtio.h>
A submission queue event.
Public Members
-
uint8_t op
Op code
-
uint8_t prio
Op priority
-
uint16_t flags
Op Flags
-
struct rtio_iodev *iodev
Device to operation on
-
void *userdata
User provided pointer to data which is returned upon operation completion
If unique identification of completions is desired this should be unique as well.
-
uint32_t buf_len
Length of buffer
-
uint8_t *buf
Buffer to use
-
uint8_t op
-
struct rtio_sq
- #include <rtio.h>
Submission queue.
This is used for typifying the members of an RTIO queue pair but nothing more.
-
struct rtio_cqe
- #include <rtio.h>
A completion queue event.
-
struct rtio_cq
- #include <rtio.h>
Completion queue.
This is used for typifying the members of an RTIO queue pair but nothing more.
-
struct rtio_executor_api
- #include <rtio.h>
-
struct rtio_executor
- #include <rtio.h>
An executor does the work of executing the submissions.
This could be a DMA controller backed executor, thread backed, or simple in place executor.
A DMA executor might schedule all transfers with priorities and use hardware arbitration.
A threaded executor might use a thread pool where each transfer chain is executed across the thread pool and the priority of the transfer is used as the thread priority.
A simple in place exector might simply loop over and execute each transfer in the calling threads context. Priority is entirely derived from the calling thread then.
An implementation of the executor must place this struct as its first member such that pointer aliasing works.
-
struct rtio
- #include <rtio.h>
An RTIO queue pair that both the kernel and application work with.
The kernel is the consumer of the submission queue, and producer of the completion queue. The application is the consumer of the completion queue and producer of the submission queue.
Nothing is done until a call is performed to do the work (rtio_execute).
-
struct rtio_iodev_api
- #include <rtio.h>
API that an RTIO IO device should implement.
-
struct rtio_iodev_sqe
- #include <rtio.h>
-
struct rtio_iodev_sq
- #include <rtio.h>
IO device submission queue.
This is used for reifying the member of the rtio_iodev struct
-
struct rtio_iodev
- #include <rtio.h>
An IO device with a function table for submitting requests.
This is required to be the first member of every iodev. There’s a strong possibility this will be extended with some common data fields (statistics) in the future.
-
RTIO_OP_NOP
RTIO SPSC API
- group rtio_spsc
RTIO Single Producer Single Consumer (SPSC) Queue API.
Defines
-
RTIO_SPSC_INITIALIZER(name, type, sz)
Statically initialize an rtio_spsc.
- Parameters
name – Name of the spsc symbol to be provided
type – Type stored in the spsc
sz – Size of the spsc, must be power of 2 (ex: 2, 4, 8)
-
RTIO_SPSC_DECLARE(name, type, sz)
Declare an anonymous struct type for an rtio_spsc.
- Parameters
name – Name of the spsc symbol to be provided
type – Type stored in the spsc
sz – Size of the spsc, must be power of 2 (ex: 2, 4, 8)
-
RTIO_SPSC_DEFINE(name, type, sz)
Define an rtio_spsc with a fixed size.
- Parameters
name – Name of the spsc symbol to be provided
type – Type stored in the spsc
sz – Size of the spsc, must be power of 2 (ex: 2, 4, 8)
-
rtio_spsc_size(spsc)
Size of the SPSC queue.
- Parameters
spsc – SPSC reference
-
rtio_spsc_reset(spsc)
Initialize/reset a spsc such that its empty.
Note that this is not safe to do while being used in a producer/consumer situation with multiple calling contexts (isrs/threads).
- Parameters
spsc – SPSC to initialize/reset
-
rtio_spsc_acquire(spsc)
Acquire an element to produce from the SPSC.
- Parameters
spsc – SPSC to acquire an element from for producing
- Returns
A pointer to the acquired element or null if the spsc is full
-
rtio_spsc_produce(spsc)
Produce one previously acquired element to the SPSC.
This makes one element available to the consumer immediately
- Parameters
spsc – SPSC to produce the previously acquired element or do nothing
-
rtio_spsc_produce_all(spsc)
Produce all previously acquired elements to the SPSC.
This makes all previous acquired elements available to the consumer immediately
- Parameters
spsc – SPSC to produce all previously acquired elements or do nothing
-
rtio_spsc_consume(spsc)
Consume an element from the spsc.
- Parameters
spsc – Spsc to consume from
- Returns
Pointer to element or null if no consumable elements left
-
rtio_spsc_release(spsc)
Release a consumed element.
- Parameters
spsc – SPSC to release consumed element or do nothing
-
rtio_spsc_consumable(spsc)
Count of consumables in spsc.
- Parameters
spsc – SPSC to get item count for
-
rtio_spsc_peek(spsc)
Peek at the first available item in queue.
- Parameters
spsc – Spsc to peek into
- Returns
Pointer to element or null if no consumable elements left
-
rtio_spsc_next(spsc, item)
Peek at the next item in the queue from a given one.
- Parameters
spsc – SPSC to peek at
item – Pointer to an item in the queue
- Returns
Pointer to element or null if none left
-
rtio_spsc_prev(spsc, item)
Get the previous item in the queue from a given one.
- Parameters
spsc – SPSC to peek at
item – Pointer to an item in the queue
- Returns
Pointer to element or null if none left
-
struct rtio_spsc
Common SPSC attributes.
Warning
Not to be manipulated without the macros!
-
RTIO_SPSC_INITIALIZER(name, type, sz)